









Nikhil Tiwari氏は、医療AI基盤企業Frekilの創業者兼CEOである。
世界の医療AI市場は急速な成長を遂げており、市場規模は2032年までに5000億ドル超に拡大すると予測されている。それでも、診断用の医療AIモデルが病院で日常的に使用される広範な導入率は見られない。
米食品医薬品局(FDA)は、脳卒中検出から乳がんスクリーニングまで、さまざまな疾患に対する診断AIモデルを承認している。しかし導入は限定的なままであり、これは病院がAIがどのように判断に至るかを確認できないことが一因である。これらのモデルはしばしばブラックボックスとして扱われる。つまり、理解ではなく答えを提供するのだ。そして医療において、理解こそがすべてである。
医療AI基盤に携わってきた経験に基づき、AIにおいて理解が不明瞭なままである理由と、透明性と正確なデータセットに焦点を当てることで、医療機関がAIプログラムを最大限に活用できる方法を見ていこう。
モデルが透明であるとはどういう意味か
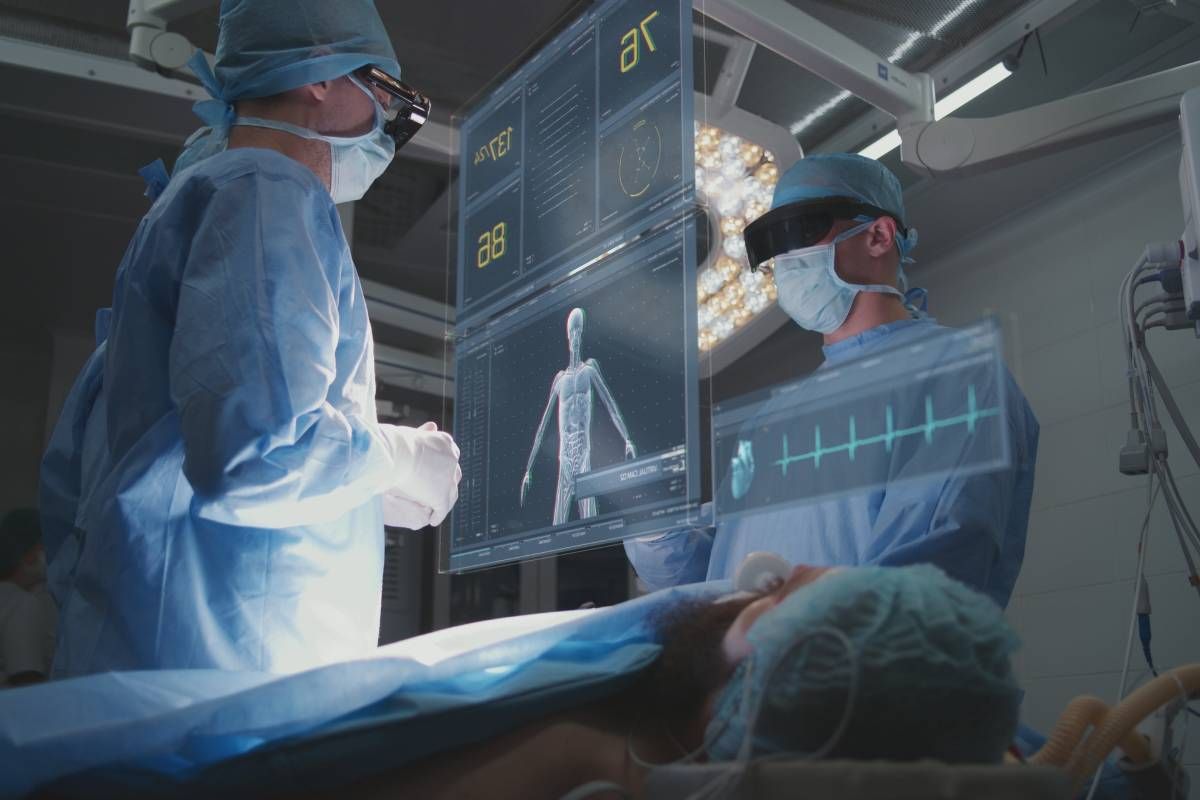
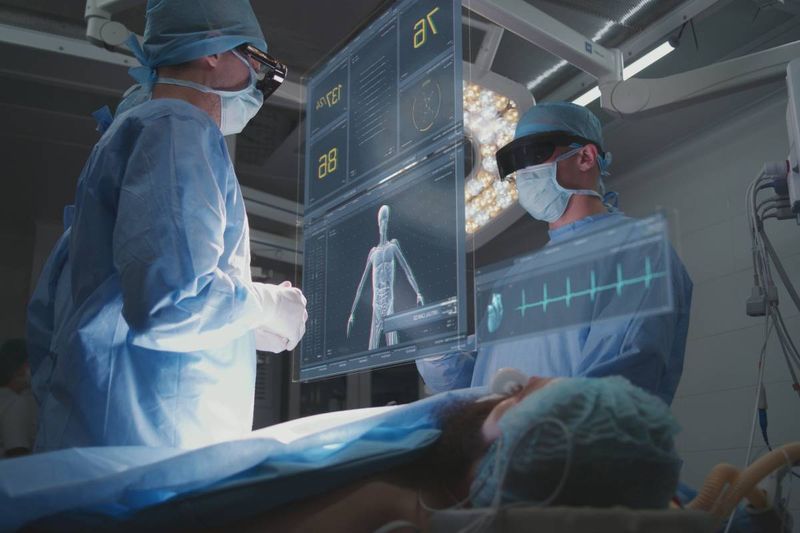
放射線科AIモデルについて話そう。これらは長い歴史を持つ。透明なモデルは、実際の放射線科医と同様に機能すべきである。放射線科医は医療スキャンを分類して診断するだけでなく、どのように結論に至ったかを示すことができる。彼らは、なぜ何かが間違っているのか、なぜそれが起こったのかを説明するための質問に答えることが期待され、確信と疑念を明確に表現する。患者にカウンセリングを行い、腫瘍が正確にどこにあり、どのように見えるかを示し、次のステップを説明する。
肝臓がんを調べるためにCTスキャンを受ける患者を想像してほしい。ブラックボックスAIは単に「陽性」とラベル付けするかもしれない。しかし透明なモデルは、腫瘍がどこに現れるか、周囲の組織とどう異なるか、なぜその所見が懸念されるかを示す。また、信頼度レベルと可能性のある曖昧さを示し、正確なデータに基づく患者の異なるニーズを考慮に入れることもできるはずだ。このように、透明性はAIを沈黙の神託から有用なパートナーへと変えることができる。
なぜ精度の数値はAIの指標として不十分なのか
病院がAIシステムを評価する際、精度の主張を額面通りに受け取ることはほとんどないことを私は観察してきた。これは賢明である。結局のところ、モデルが偏ったデータや不完全なデータで訓練された場合、98%の精度スコアはほとんど意味を持たない。その理由は以下の通りだ。
• 訓練データに内在するバイアス:多くのモデルは、しばしば単一の地域や画像装置タイプからの限定的なデータセットで構築されている。これは、ある病院で素晴らしいパフォーマンスを発揮するプログラムが、別の病院では予測不可能なパフォーマンスを示す可能性があることを意味する。
• 説明可能性の欠如:臨床医は、特に患者の治療がそれに依存する場合、モデルがなぜその決定を下したかを知る必要がある。追跡可能な推論がなければ、誰が責任を負うのかを知ることが難しくなる。
• 規制と責任に関する懸念:不透明なAIシステムが症例を誤診した場合、病院は法的および倫理的リスクに直面する。透明性は優れた科学であるだけでなく、優れたコンプライアンスでもある。
医療AIに内在するバイアスはどのように入り込むのか
多くの大規模医療画像データセットは、北米とヨーロッパの患者で不均衡に構成されており、アフリカ系アメリカ人、インド人、ラテン系、東南アジア人の代表性は限定的である。これが重要なのは、異なる人口統計グループが異なる疾患パターン、ベースラインの解剖学的構造、有病率を示す可能性があるためだ。
例えば、アフリカ系アメリカ人患者は特定の心血管疾患の発症率が高い。インド人集団は代謝性疾患や肝疾患において異なるパターンを示すことが多く、体組成はグループ間で異なる可能性があり、CTやMRIで臓器がどのように見えるかを微妙に変化させる。これらの変動が訓練データで欠落しているか過小評価されている場合、モデルは多数派クラスに過度に調整される。多数派の集団では極めて良好なパフォーマンスを発揮する一方で、そうでない集団では静かに性能が低下する可能性がある。このクラスの不均衡は、所見の見逃し、偽陽性、人種や民族間での不平等なパフォーマンスにつながる可能性がある。
医療において、わずかなバイアスでさえ技術的な欠陥にとどまらない。それは臨床的および倫理的リスクになり得る。なぜなら、あるグループではうまく機能するが別のグループでは失敗するモデルは、意図せず健康格差を拡大する可能性があるからだ。
評価データセットを準備してバイアスを防ぐ
訓練データにバイアスがある可能性があるため、病院が独自の実世界サンプルでAIのパフォーマンスを検証することが重要である。実際には、これは組織の特定の環境を反映する評価データセットを構築することを意味する。異なるスキャナー、人口統計、地域の疾患パターン、ワークフローはすべて、AIモデルがどの程度うまく機能するかに影響を与える。
病院は、さまざまな機器、患者の年齢、臨床状態からの画像を含む代表的なデータセットを組み立てるのに数か月を費やすことが多い。これはコストと時間がかかる可能性があるが、私の経験では、安全な展開が目標である場合、代替手段はない。このステップなしでは、精度の主張はマーケティングの数字に過ぎない。
シリコンバレーでの内部テスト中に良好なパフォーマンスを示すモデルは、インドの地方病院やヨーロッパの三次医療センターでは静かに失敗する可能性がある。地域での評価は、病院がこれらの失敗から自らと患者を守るのに役立つ。
今日のワークフローにおいてAIモデルが最も適合するのはどこか
AIは代替としてではなく、拡張レイヤーとして、つまり第二の読影者、トリアージアシスタント、または品質管理メカニズムとして最高のパフォーマンスを発揮する。例えば、AIは緊急スキャンを優先してより迅速なレビューを行い、放射線科医が再確認すべき潜在的な見逃しにフラグを立てることができる。私の経験では、最も成功した展開は、AIが意思決定を盲目的に自動化するのではなく、支援すべきであることを認識している。
結論
医療に必要なのは正確な機械だけではない。作業を示す機械が必要なのだ。透明なAIは、臨床医に画像のどの領域が決定に影響を与えたか、モデルがどのようなパターンを見たか、不確実性がどこにあるかについての可視性を提供できる。
正確なデータセットは、この透明性における重要な第一歩である。AIが構造化された推論、段階的な説明、インタラクティブな対話が可能になるにつれて、信頼は自然に高まるはずだ。医師は、研修医を教えるのと同じように、モデルの結論に異議を唱え、検証し、洗練させることができる。
医療AIの未来は、最も正確なモデルによってではなく、明確にコミュニケーションし、各病院の環境に安全に適応し、臨床医をループに留めるモデルによって決定されると私は信じている。AIが「何を」だけでなく「なぜ」を説明できるようになれば、病院はこれらのツールを大規模に導入することにより大きな成功を収めることができる。































