











人工知能は、人間が目で見たときとはまったく異なる形で映像の内容を理解している。その違いは「教育方針」によるものであることが、大阪大学の研究で判明した。詰め込み教育ではなく、自発的な学習によって人工知能も人間と同じものの見方を自然に養うというのだ。
ChatGPTなどの大規模言語モデル(LLM)には、トランスフォーマーと呼ばれる文章解析技術が使われている。言葉を細かい断片に切り分けて、それぞれを解析して、その結果を総合して意味を推論する。映像の学習に関しては、その手法を映像に応用したビジュアルトランスフォーマー(ViT)が用いられる。問題は、ViTに映像の把握方法をどうやって教えるかだ。
大阪大学大学院生命機能研究科ダイナミックブレインネットワーク研究室の北澤茂教授らによる研究チームは、まったく同じ構造のViTを使って、膨大な映像データと正解を「先生」が「生徒」に教え込む詰め込み教育型の学習法(SL法)と、先生が正解を示さず、いわば生徒といっしょに考える自発的な学習方法(DINO法)との比較を行った。ここで言う自発的学習方法とは、先生役のViTを生徒役のViTが模倣し、先生ViTが生徒ViTからフィードバックを得るという相互依存的に画像から得られる情報量を最大化していく「DINO型」と呼ばれるものだ。
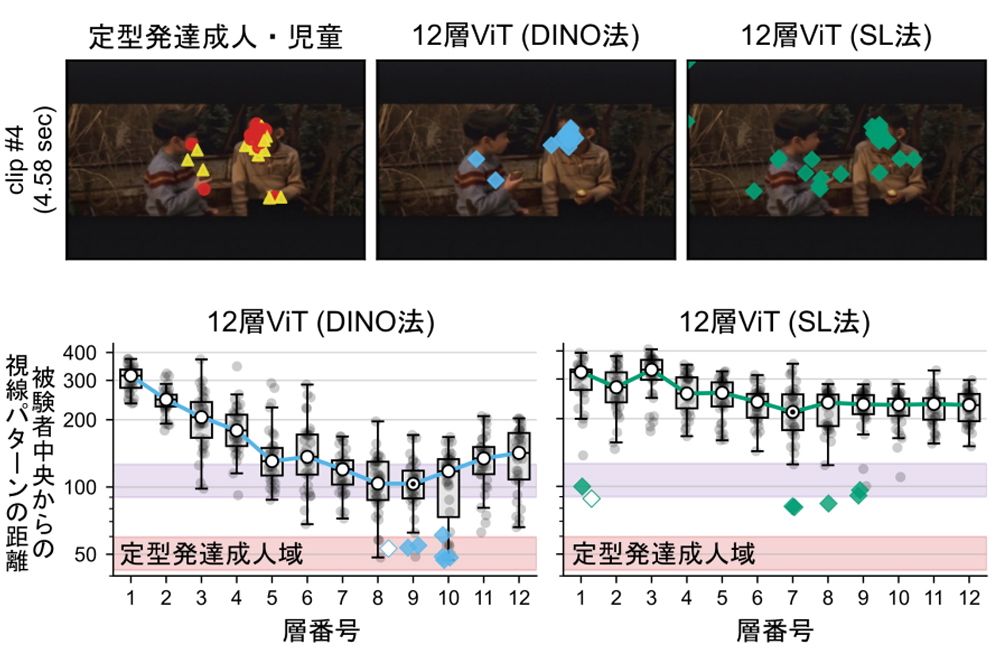
それによると、詰め込み型ではViTは人間とはまったく違う部分に注目するようになるのに対して、自発的学習型では、映像に映っている人の顔、体全体、背景と、一般的な人間と同じ部分に注目するようになることがわかった。たとえば、人の「顔」の概念は一切教えていないのに自分でわかるようになり、テレビ番組や映画を見せると、その場面の主役の顔に注意を向けるようになったということだ。
また、人の視覚認知を検査するために心理学で用いられるさまざまなパターンを見せたところ、自発的学習で育ったViTは、人間と同じ部分に注目することもわかった。人間の子どもは「これが顔だよ」などと誰かに教わることなく、自分でさまざまな要素を学習して「顔」を認識するようになるが、それと同じことをコンピューターも行うようになるわけだ。

じつは、人間の脳が視覚情報をどう処理しているかはよくわかっていない。研究チームはこの研究成果を、人との相性のいい人工知能の開発につながるだけでなく、「人間の育て方にも大いに示唆を与える」と話している。






























